Speech To Text
Introduction
The Xdroid Speech To Text API enables digital transformation in contact centers through voice and text solutions based on artificial intelligence and machine learning.
API specification
Base URL
https://api-prd.kpn.com/data/kpn/voiceanalytics/
Conceptual model

Definitions
Codec
A codec is a device or computer program which encodes or decodes a digital data stream or signal. Codec is short for coder-decoder.
G.711
G.711 is a narrowband audio codec, which defines two main compandings (compressing/expanding) algorithms, the μ-law algorithm and the A-law algorithm.
ISO
International Organization for Standardization (ISO) is an international standard-setting body.
MP3
MP3 is a coding format for digital audio.
MP4
MPEG-4 Part 14 or MP4 is a digital multimedia container format.
OGG
Ogg is a free, open multimedia container format.
Opus
Opus is an audio coding format using lossy compression.
PCI
Payment Card Industry (PCI) compliance is mandated by credit card companies to help ensure the security of credit card transactions in the payments industry.
PCM
Pulse Code Modulation (PCM) is an audio format. PCM is both uncompressed and lossless.
WAV
Waveform Audio File Format is an audio file format standard, developed by IBM and Microsoft.
API workflow
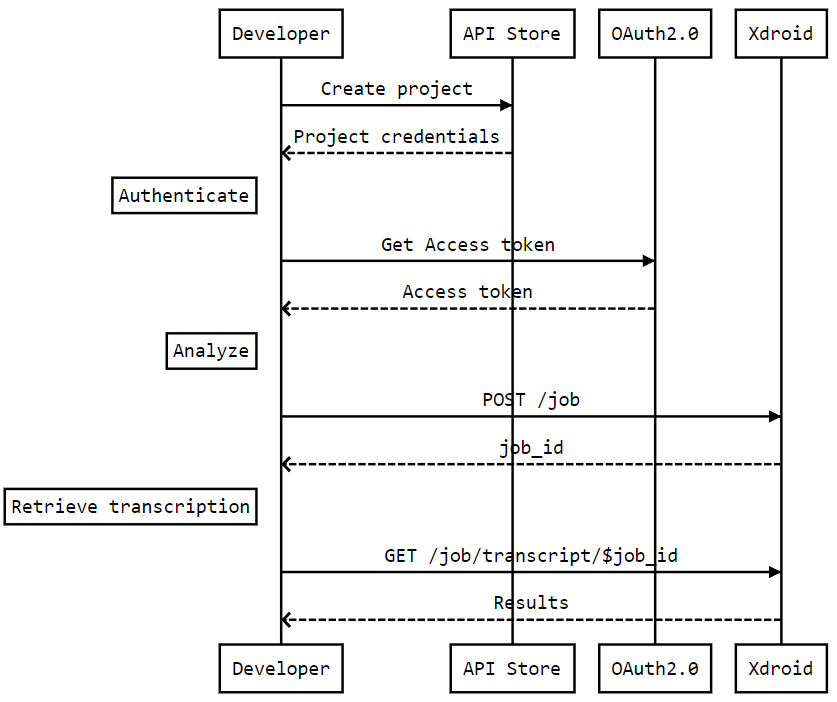
Requirements
- Accepted container formats:
- .wav
- .mp3 / .mp4
- .opus / .ogg
- Preferred audios that provides the best quality:
- Bitrate: 64 Kbit/s per channel (stereo recording is supported).
- Sample rate: 8 KHz / 16 KHz.
- Uncompressed / lossless telephony codecs (PCM Linear, G711 a-law/u-law).
Features and constraints
Features
- API provides speech to text transcriptions based on search word volume.
- Voice analytics system provides additional emotion analysis, keyword detection and semantic capabilities along with full quality evaluation for call centers.
Constraints
- Audio file should not be greater than 150 M bytes.
Getting started
Make sure you've read Getting Started for more info on how to register your application and start trying out our APIs.
Authentication
The API follows the KPN Store API authentication standard to secure the API. It includes the use of OAuth 2.0 client_id and client_secret to receive an access token.
Go to the Authentication tab on top of this page to find out how to:
- Authenticate to an API using cURL.
- Authenticate to an API on SwaggerHub.
- Import Open API Specifications (OAS), also called Swagger files into Postman.
How to...
Submit audio files for analysis
This endpoint lets you submit audio files to start a new voice analytics job.
Recommended formats are:
- WAV container (PCM Linear 16 bit, G711 μ-law/A-law) is recommended.
- MP3/OPUS recordings are also supported but depending on the compression level, it may affect transcription accuracy.
The supported content type is multipart/form-data.
Request
POST /job
Upload the audio file and send the language config in the body.
cURL request example
curl -X POST "https://api-prd.kpn.com/data/kpn/voiceanalytics/job" -H "accept: application/json" -H "Authorization: Bearer *****************" -H "Content-Type: multipart/form-data" -F "config={"language":"en","recording_start":"" }" -F "audio_file=@speech_orig.wav;type=audio/wav"
| Body parameter | Type | Description |
|---|---|---|
audio_file=@ |
multipart/form-data | Audio file. File size limit: 100 Mbyte for each file. Example: /Audios/0036550e-720f-1239-0b99-eecf4973.wav. |
config= |
object | JSON object containing language and recording_start parameters.Example: {"language":"en","recording_start":"" } |
language |
string | The parameter language is required in ISO language code. Supported language codes: Global English: en Global Spanish: es Dutch: nl French: fr Example: "language":"en" |
recording_start |
integer | Day and time when the recording starts. Optional Format: YmdHis. Example: "recording_start":"20201216081228". |
Response
The response returns the unique job_id. Save it to retrieve the transcription in later requests.
Response example
{
"job_id": 12
}
Retrieve transcription
This endpoint retrieves the JSON transcript of a finished transcription job. Send the unique job_id as a path parameter.
Please do not use intervals that are shorter than 10 seconds to check the status to avoid a throttle penalty.
Request
GET /job/transcript/$job_id
cURL request
curl -X GET "https://api-prd.kpn.com/data/kpn/voiceanalytics/job/13" -H "accept: application/json" -H "Authorization: Bearer *****************"
Response
Expected flow of statuses is queued > processing > analyzed.
Please calculate with real-time equivalent (RTE) of 1. That means that a minute length conversation will take approximately the same time as the length of the recording.
Response - Processing status
{
"job": {
"job_id": 12,
"created_at": "2020-12-16 15:26:39",
"audio_file": "xdroid-voiceanalytics-sample_20201216152639.wav",
"status": "processing"
},
"results": [
}
If the job status gets to analyzed, the request will retrieve analytics results in the [results] block. The results are in JSON array format.
Response - Analyzed status with results
{
"job": {
"job_id": 12,
"created_at": "2020-12-16 15:26:39",
"audio_file": "xdroid-voiceanalytics-sample_20201216152639.wav",
"status": "analyzed"
},
"results": [
{
"data_type": "TRANSCRIPT", // Type of data, see table below
"data_channel": 1, // Detected channel in stereo, where 1 = first, 2 second channel
"data_value": "welcome", // A transcribed word
"data_detect_start": 570, // Start time in milliseconds
"data_detect_end": 1020, // End time in milliseconds
"data_length": 450, // Length of block in milliseconds
"data_probability": 1 // Probability of result
},
{
"data_type": "TRANSCRIPT",
"data_channel": 1,
"data_value": "to",
"data_detect_start": 1020,
"data_detect_end": 1140,
"data_length": 120,
"data_probability": 1
},
{
"data_type": "TRANSCRIPT",
"data_channel": 1,
"data_value": "voice",
"data_detect_start": 1140,
"data_detect_end": 1440,
"data_length": 300,
"data_probability": 1
},
{
"data_type": "TRANSCRIPT",
"data_channel": 1,
"data_value": "analytics",
"data_detect_start": 1440,
"data_detect_end": 2050,
"data_length": 610,
"data_probability": 1
},
}
| Parameter | Description |
|---|---|
data_type |
TRANSCRIPT. Word-level transcription. Data value contains the word, data_probability is the internal confidence level. |
data_channel |
Detected channel in stereo, where 1 = first, 2 second channel. Example: 1 |
data_value |
Transcribed word. Example: welcome |
data_detect_start |
Start time in milliseconds. Example: 8820 |
data_detect_end |
End time in milliseconds. Example: 9070 |
data_length |
Length of block in milliseconds. Example: 250 |
data_probability |
Probability of result. Example: 0.83 |